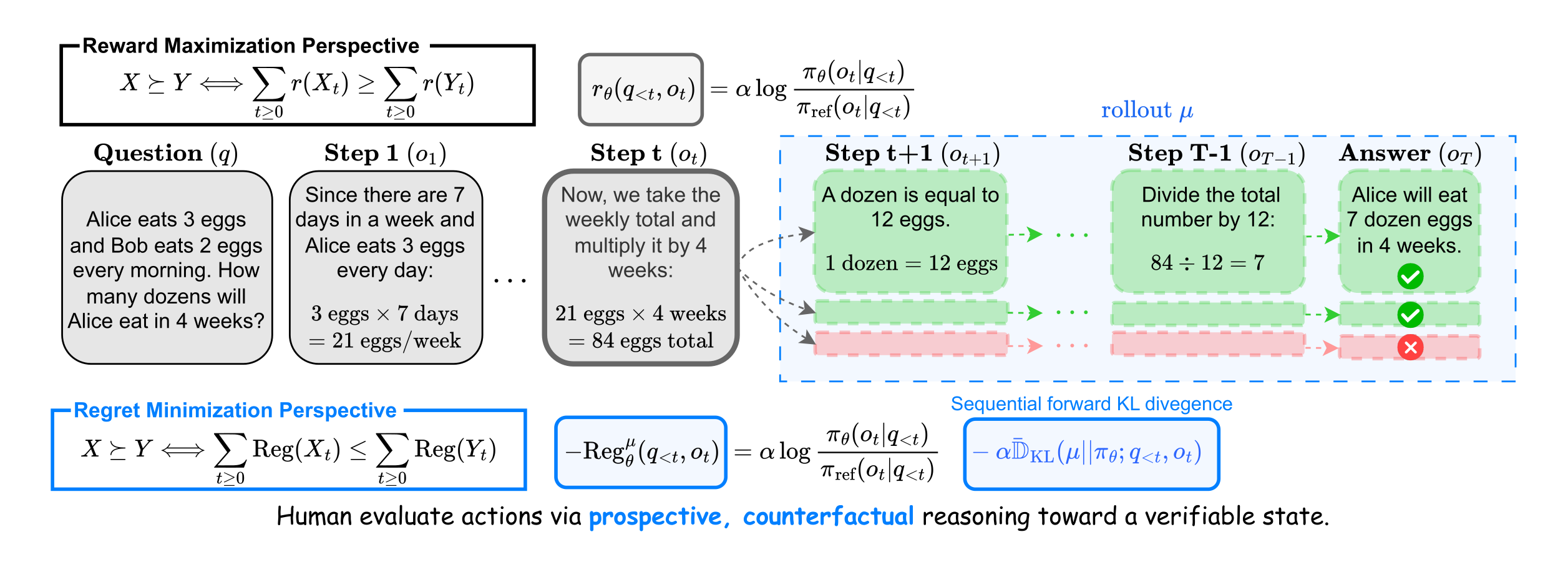
Reinforcement learning with verifiable rewards has driven progress on reasoning-intensive tasks, but many realistic language tasks cannot be equipped with reliable automated verifiers. In such settings, learning systems increasingly rely on human preference feedback, making it important to ask how such feedback should be interpreted.
This paper introduces Regret-based Preference Optimization (RePO), which views human preferences not as immediate reward labels, but as prospective and counterfactual assessments of relative suboptimality. Instead of asking which partial trajectory has larger local utility, RePO asks which behavior is closer to optimal behavior after considering plausible future continuations and alternative actions.
Under a KL-regularized reinforcement learning framework, this perspective yields a regret decomposition compatible with direct preference optimization. Experiments on human preference alignment and mathematical reasoning benchmarks show that RePO improves over DPO-style baselines and remains practical through RePO_det, a behavior-policy-free deterministic approximation.
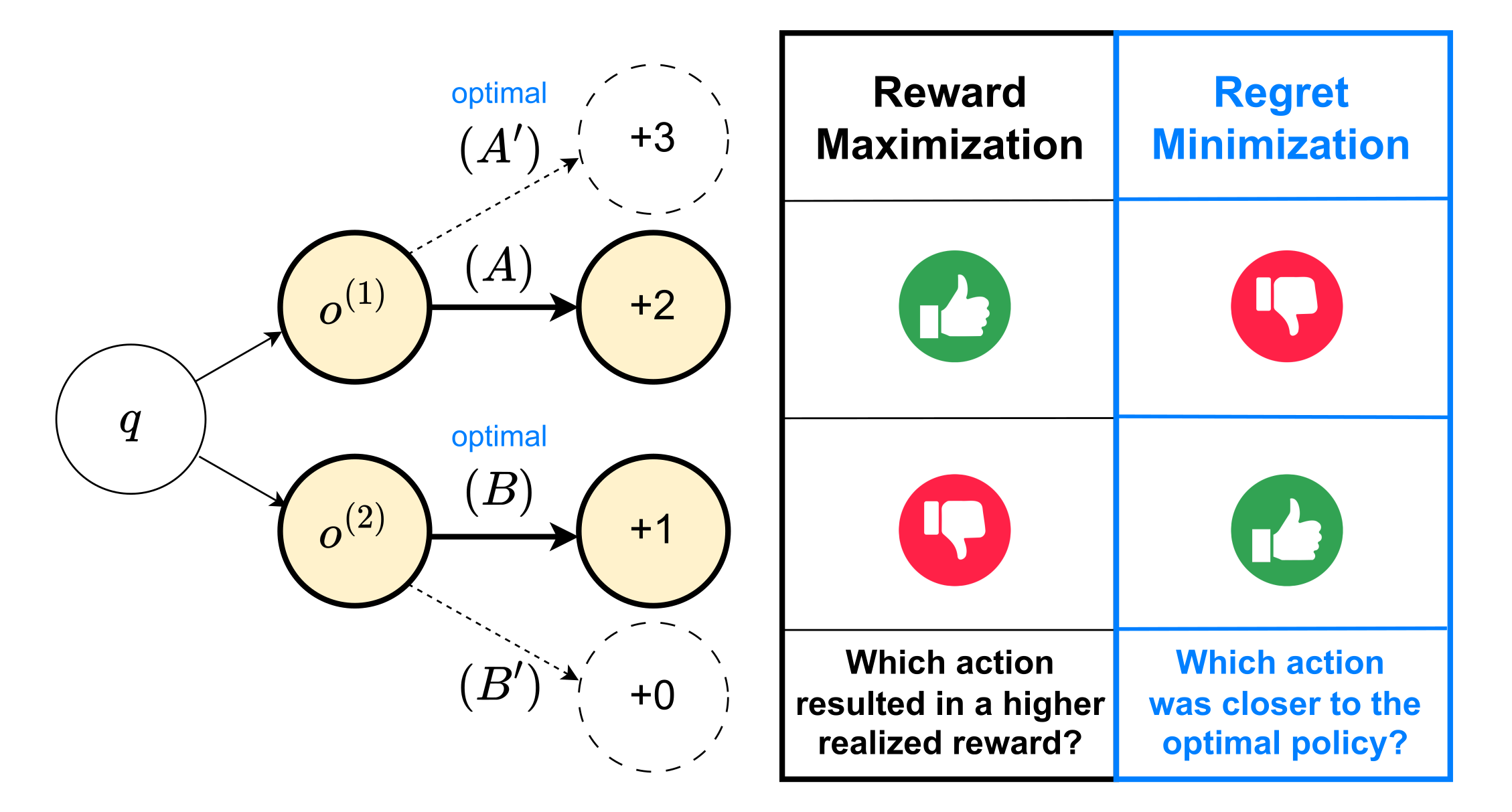
The paper argues that human judgments over intermediate reasoning are not purely local. Evaluators mentally anticipate future outcomes and compare the observed behavior against plausible alternatives. This motivates a regret-minimization view: Preferences should reflect closeness to optimal behavior, not only realized reward.
A partial reasoning segment may be preferred when it lies on a plausible path to a good future outcome, even if it has not yet received any immediate reward.
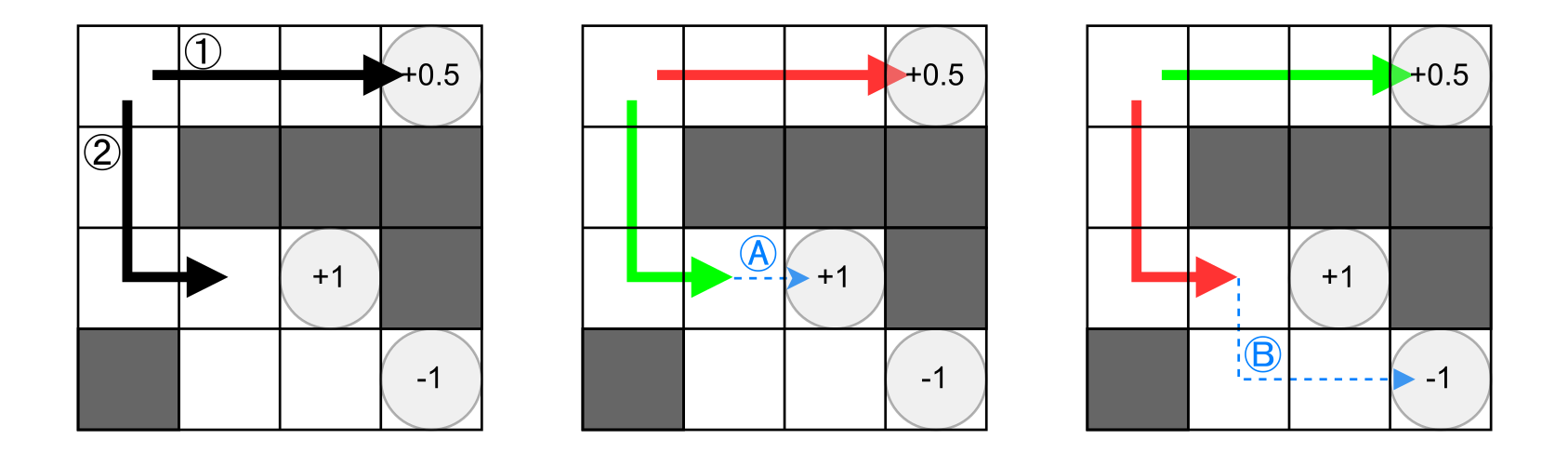
A realized outcome can be worse than another, yet the chosen action can still be closer to the optimal policy under plausible counterfactual alternatives.
RePO instantiates the preference score with negative regret. For context $q_{<t}$ and output $o_t$, regret compares the optimal value at the current context with the behavior-policy value of taking the observed output and then following the behavior policy $\mu$.
The first term is a local relative-likelihood term analogous to DPO. The second term is a sequential forward KL divergence that measures how far the behavior policy deviates from the optimal policy along future rollouts, defined as
This makes the objective explicitly behavior-aware in offline or heterogeneous preference data.
Exact sequential KL computation is expensive, so the practical estimator reuses observed trajectories as finite-horizon rollouts. When behavior-policy log-probabilities are known, RePO uses them directly:
When the behavior policy is unavailable, RePO_det replaces it with a deterministic pseudo-policy concentrated on the observed trajectory. This keeps the regret structure while making the method usable for pre-collected offline preference datasets:
Preferences over partial reasoning are interpreted through likely future continuation.
Actions are compared against alternatives that could have been taken at the same context.
The objective accounts for rollout likelihoods instead of assuming on-policy preference data.
Why does regret-based preference learning outperform reward-based alternatives? Beyond the off-policy correction in the regret decomposition above, the regret objective structurally internalizes a pessimistic inductive bias that aligns with how humans evaluate incomplete reasoning: regret at a successful terminal state is dominated by the expected regret at any intermediate partial context along the same trajectory.
The assumption behind this property is mild: the behavior policy $\mu$ should be closer to the optimal policy $\pi^*$ than to the reference policy $\pi_{\mathrm{ref}}$ in KL divergence — a condition that naturally holds along trajectories that reach a verifier-accepted outcome.
Under this condition, for any verifier-accepted output $o_T^{\star}$ and any earlier context $q_{<t}$ on the same trajectory, the regret of the full success is upper-bounded by the expected regret at the partial context:
Intuitively, masking parts of a successful trajectory introduces uncertainty about its eventual completion, so a partial context is judged more harshly than the corresponding fully revealed accepted trajectory. The regret objective therefore prefers complete, verifier-consistent reasoning over partial reasoning without requiring any auxiliary masked-data augmentation — the bias is encoded in the loss itself.
This is the structural reason RePO achieves stronger sample efficiency than DPO-style baselines: where DPO must rely on externally constructed contrastive pairs to teach this preference, RePO inherits it directly from the regret decomposition, as we verify empirically below.
The experiments ask whether RePO improves human preference alignment and mathematical reasoning, whether RePO_det remains effective without behavior-policy access, and whether regret minimization internalizes the pessimistic inductive bias toward incomplete successful trajectories.
Best results are bold; second-best results are underlined.
| Backbone | Method | AlpacaEval 2 | Arena-Hard | MT-Bench | ||
|---|---|---|---|---|---|---|
| LC (%) | WR (%) | WR (%) | GPT-4.1 | GPT-5.1 | ||
| Qwen3-1.7B-Base | Base | 8.27 | 6.05 | 10.4 | 5.09 | 4.41 |
| DPO | 23.90 | 25.84 | 23.4 | 6.00 | 4.81 | |
| IPO | 24.46 | 26.37 | 21.9 | 6.56 | 5.10 | |
| RPO | 18.63 | 15.47 | 17.7 | 5.98 | 5.13 | |
| KTO | 34.73 | 38.93 | 30.4 | 6.92 | 5.32 | |
| TDPO | 12.24 | 10.72 | 14.5 | 5.56 | 4.73 | |
| RePO | 36.61 | 43.66 | 27.1 | 6.88 | 5.43 | |
| RePO_det | 34.95 | 41.42 | 26.6 | 6.89 | 5.16 | |
| Qwen3-4B-Base | Base | 12.80 | 11.62 | 25.4 | 5.56 | 4.83 |
| DPO | 32.89 | 33.92 | 44.5 | 6.79 | 5.74 | |
| IPO | 36.43 | 38.63 | 47.8 | 7.43 | 6.14 | |
| RPO | 29.51 | 28.23 | 41.9 | 7.05 | 6.13 | |
| KTO | 52.31 | 55.78 | 63.9 | 8.22 | 6.93 | |
| TDPO | 17.97 | 17.08 | 30.9 | 6.24 | 5.38 | |
| RePO | 55.08 | 60.12 | 60.1 | 8.09 | 6.78 | |
| RePO_det | 51.66 | 55.53 | 59.9 | 8.18 | 6.97 | |
| Backbone | Method | GSM8K | MATH | MATH500 | AMC23 | Minerva |
|---|---|---|---|---|---|---|
| Qwen3-1.7B-Base | Base | 61.71 | 48.50 | 48.60 | 30.00 | 9.60 |
| DPO | 77.33 | 53.44 | 52.80 | 32.50 | 16.91 | |
| RPO | 69.07 | 50.32 | 51.40 | 30.00 | 13.24 | |
| IPO | 79.45 | 51.76 | 53.40 | 20.00 | 16.54 | |
| KTO | 79.68 | 54.42 | 56.60 | 35.00 | 17.28 | |
| TDPO | 64.06 | 48.80 | 52.20 | 25.00 | 9.93 | |
| RePO | 80.52 | 54.50 | 57.40 | 30.00 | 20.59 | |
| RePO_det | 80.74 | 54.84 | 54.40 | 25.00 | 25.74 | |
| Qwen3-4B-Base | Base | 78.77 | 61.20 | 64.20 | 32.50 | 19.90 |
| DPO | 87.87 | 56.66 | 57.80 | 35.00 | 27.21 | |
| RPO | 90.30 | 63.44 | 66.80 | 47.50 | 22.79 | |
| IPO | 88.86 | 58.36 | 57.40 | 45.00 | 27.57 | |
| KTO | 90.83 | 67.38 | 67.60 | 55.00 | 25.74 | |
| TDPO | 90.67 | 62.76 | 64.80 | 47.50 | 24.26 | |
| RePO | 90.60 | 65.54 | 66.20 | 42.50 | 22.43 | |
| RePO_det | 91.05 | 65.72 | 65.40 | 47.50 | 23.50 |
Offline preference datasets often do not expose the behavior policy that generated each response. RePO_det approximates each observed trajectory as if it were generated by a deterministic policy, which makes regret-based training usable in behavior-agnostic and cross-model settings.
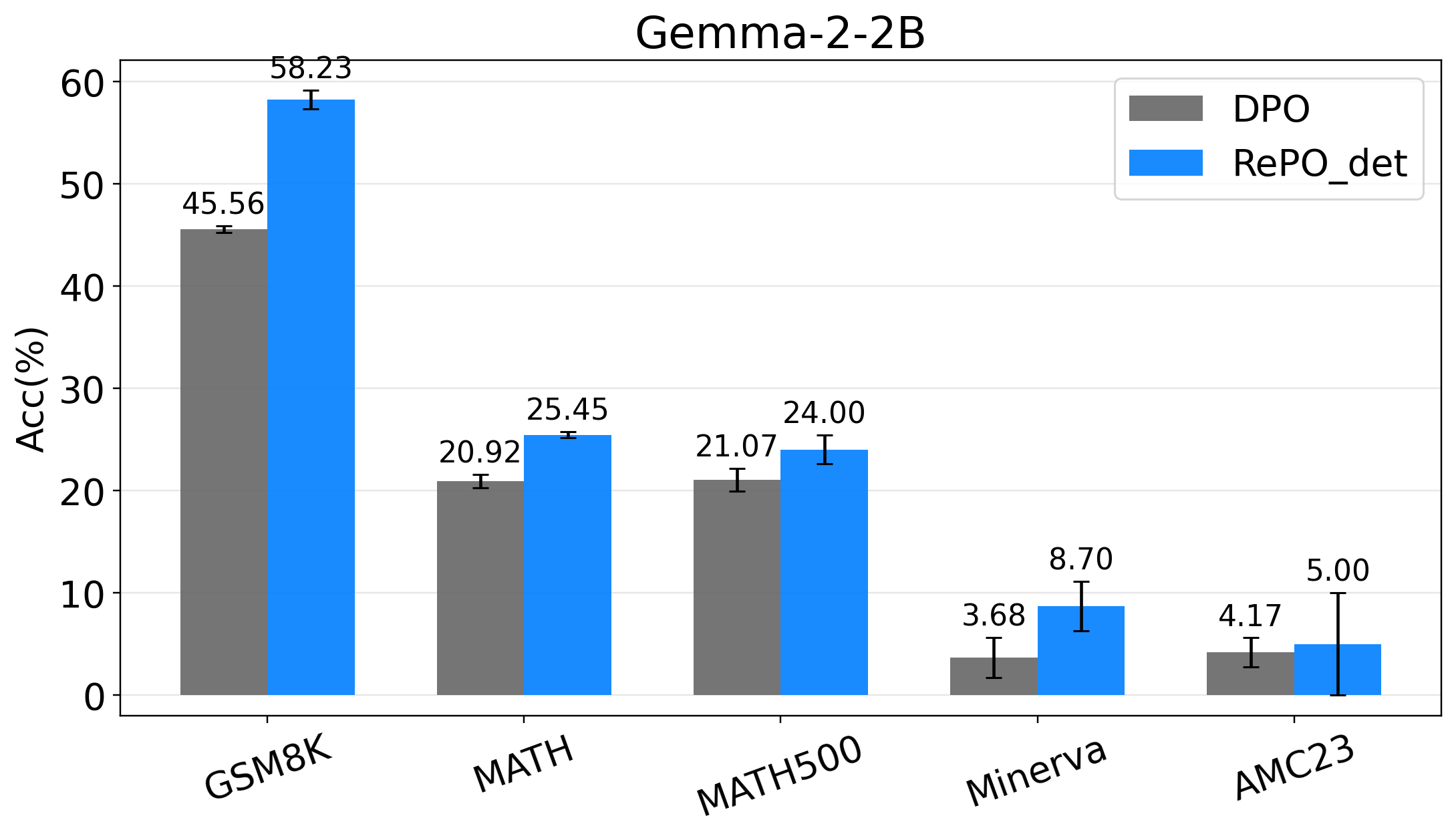
RePO structurally encodes the bias that incomplete successful trajectories should be evaluated pessimistically because their final completion is uncertain. In the masked-data study, DPO improves as more augmented pairs are provided, while RePO remains strong without requiring this additional supervision.
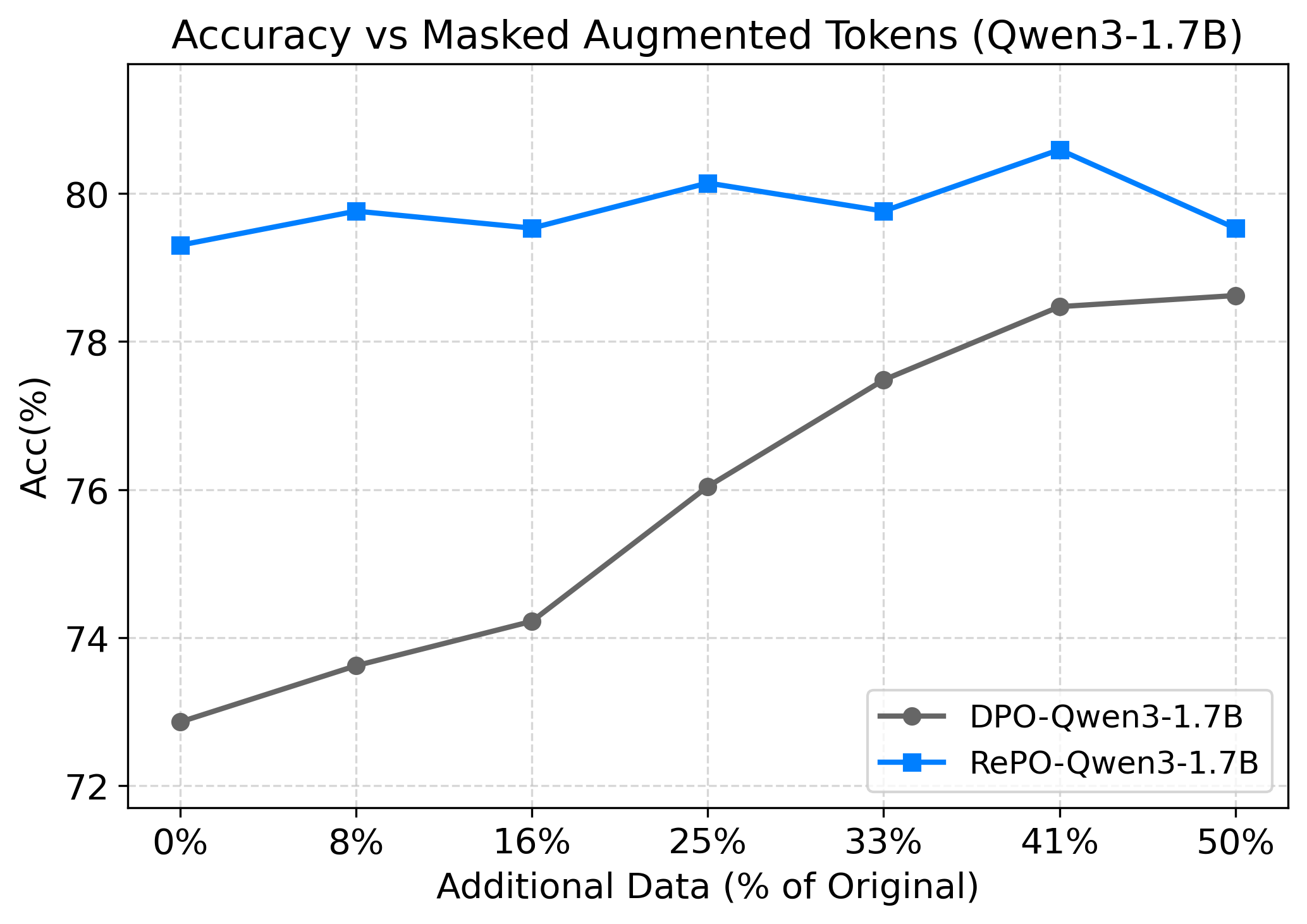
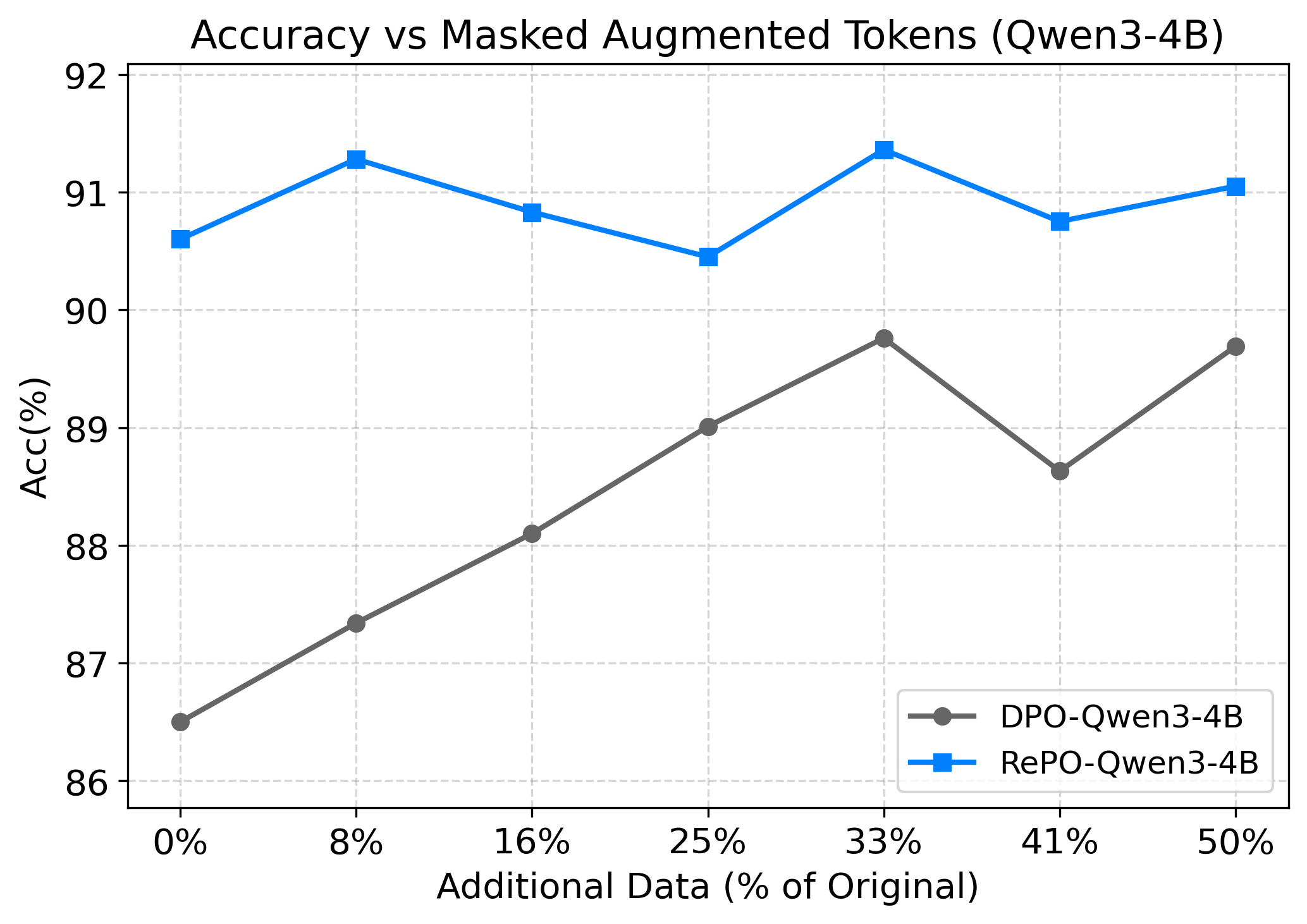
| Model | Method | GSM8K | MATH | MSE |
|---|---|---|---|---|
| Qwen3-1.7B | DPO | 72.55 | 52.14 | 0.073 |
| DPOmasked | 77.71 (+5.16) | 53.52 (+1.38) | 0.056 | |
| RePO | 80.52 | 54.50 | 0 | |
| RePOmasked | 80.29 (-0.23) | 55.26 (+0.76) | - | |
| Qwen3-4B | DPO | 85.22 | 63.70 | 0.066 |
| DPOmasked | 88.63 (+3.41) | 64.46 (+0.72) | 0.054 | |
| RePO | 90.60 | 65.54 | 0 | |
| RePOmasked | 90.98 (+0.38) | 65.46 (-0.08) | - |
RePO models preferences as prospective and counterfactual judgments over reasoning trajectories.
The objective combines a local DPO-like term with a long-horizon behavior-deviation term.
RePO_det supports offline preference data without explicit behavior-policy metadata.
@inproceedings{kim2026regret,
title = {A Regret Minimization Framework on Preference Learning in Large Language Models},
author = {Kim, Suhwan and Cho, Taehyun and Kim, Geonhyeong and Kim, Yujin and Jang, Youngsoo and Lee, Moontae and Lee, Jungwoo},
booktitle = {Proceedings of the 43rd International Conference on Machine Learning},
year = {2026}
}